Artificial intelligence systems that understand human language depend heavily on high-quality speech datasets. From voice assistants and automated call centers to healthcare dictation systems and smart devices, speech-enabled technologies rely on accurately labeled audio data. At the core of these datasets lies speech transcription, the process of converting spoken language into written text.
For machine learning models to recognize, interpret, and respond to speech effectively, audio data must be carefully transcribed and annotated. This task is typically handled by a specialized data annotation company or through data annotation outsourcing, allowing organizations to build scalable and accurate datasets without managing large in-house teams.
In AI dataset creation, different types of speech transcription are used depending on the application, training objectives, and linguistic complexity of the dataset. Understanding these transcription types helps businesses choose the right approach when working with an audio annotation company or outsourcing transcription tasks.
This article explores the most common types of speech transcription used in AI dataset creation and how they support the development of advanced speech recognition models.
The Role of Speech Transcription in AI
Speech transcription is a foundational component of speech recognition and natural language processing systems. AI models learn patterns between audio signals and textual representations by analyzing large volumes of transcribed speech data.
When organizations partner with a data annotation company, trained annotators listen to audio recordings and convert them into text according to strict guidelines. These transcripts allow AI models to understand pronunciation, accents, speech patterns, and contextual language usage.
High-quality speech transcription datasets help AI systems perform tasks such as:
-
Voice command recognition
-
Speech-to-text conversion
-
Conversational AI interactions
-
Customer support automation
-
Language translation systems
Because of the complexity and scale of these datasets, many businesses rely on data annotation outsourcing and audio annotation outsourcing to maintain quality, scalability, and consistency.
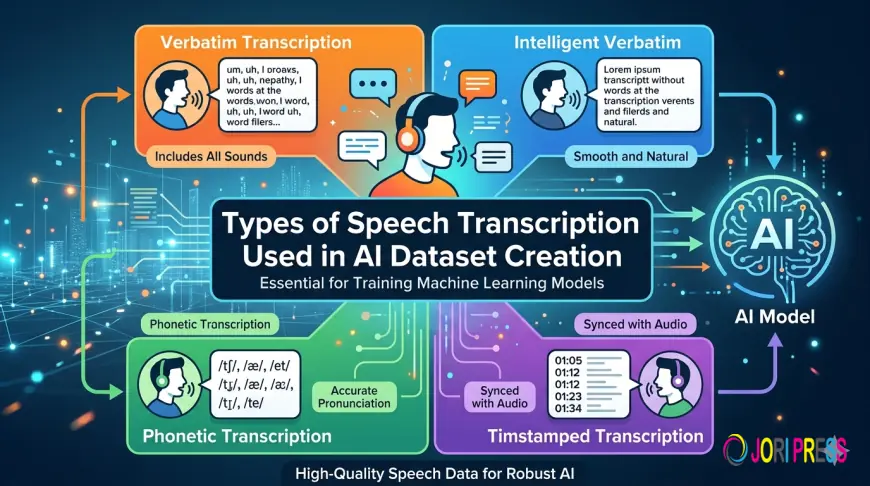
Verbatim Transcription
Verbatim transcription captures spoken language exactly as it occurs in the audio recording. This includes filler words, pauses, repetitions, stutters, and background speech elements.
For example, phrases like “um,” “uh,” or repeated words are included in the transcript.
Why Verbatim Transcription Matters for AI
Verbatim transcription helps AI systems learn the natural patterns of human speech. Real-world conversations rarely follow perfect grammar or sentence structures. By training on verbatim transcripts, speech recognition models can better interpret spontaneous speech.
This transcription type is commonly used in:
-
Conversational AI training datasets
-
Customer service call recordings
-
Dialogue-based AI assistants
An experienced audio annotation company ensures that every nuance of the audio recording is preserved, which improves the realism and accuracy of AI training data.
Clean Read Transcription
Clean read transcription removes filler words, stutters, and speech errors while preserving the intended meaning of the conversation. The transcript becomes easier to read while still reflecting the speaker’s message.
For instance, a sentence like:
“Uh, I think we should maybe start the meeting at ten.”
May become:
“I think we should start the meeting at ten.”
Applications in AI Dataset Creation
Clean read transcription is useful when the focus is on semantic meaning rather than speech patterns. Many natural language processing systems benefit from structured and grammatically clear text.
Common use cases include:
-
Language understanding models
-
Text-based analytics systems
-
Chatbot training datasets
Companies that use data annotation outsourcing often request clean transcripts when building datasets focused on intent recognition or semantic understanding.
Intelligent Transcription
Intelligent transcription is a refined form of transcription where speech is converted into well-structured text while maintaining the meaning and context of the conversation. Unlike clean read transcription, it may also involve minor corrections to grammar, sentence structure, and clarity.
This approach requires skilled annotators who can interpret spoken language and produce accurate written text.
Why Intelligent Transcription is Important
Intelligent transcription is often used in AI systems that prioritize readability and contextual accuracy. It is particularly helpful when speech recordings contain fragmented sentences or informal speech patterns.
Typical applications include:
-
Knowledge management systems
-
AI training for summarization models
-
Content indexing and search systems
Partnering with a professional data annotation company ensures that intelligent transcription maintains consistency across large datasets.
Phonetic Transcription
Phonetic transcription focuses on the pronunciation of words rather than their spelling. Using phonetic symbols, annotators capture the exact sounds spoken by the speaker.
This method is particularly important for training speech recognition systems that must understand diverse accents and pronunciation patterns.
Use Cases in AI
Phonetic transcription helps AI models analyze subtle differences in speech sounds, making it valuable for:
-
Accent recognition systems
-
Language learning applications
-
Speech therapy technologies
-
Advanced speech recognition models
Because phonetic annotation requires specialized linguistic expertise, many organizations rely on audio annotation outsourcing to obtain accurate phonetic datasets.
Time-Stamped Transcription
Time-stamped transcription aligns spoken words with specific timestamps in the audio recording. Each segment of text is linked to the exact moment it occurs in the audio.
For example:
[00:01:05] Welcome to the meeting.
[00:01:08] Let’s begin with the project update.
Importance in AI Dataset Development
Time-aligned transcripts allow AI models to synchronize text with audio signals. This is essential for training speech recognition systems that must process real-time audio streams.
Time-stamped transcription is widely used in:
-
Automatic speech recognition (ASR) training
-
Video captioning systems
-
Multimedia indexing tools
-
Voice search technologies
An experienced audio annotation company ensures accurate alignment between spoken words and timestamps, which significantly improves model training.
Speaker-Labeled Transcription
Speaker-labeled transcription identifies and labels different speakers in an audio recording. Each line of dialogue is attributed to a specific speaker.
Example:
Speaker 1: Hello everyone, welcome to the call.
Speaker 2: Thank you for having us.
Why Speaker Labeling Matters
In real-world scenarios, audio recordings often involve multiple participants. AI systems must learn to distinguish between different voices and understand conversational dynamics.
Speaker-labeled transcription supports the development of:
-
Meeting transcription systems
-
Call center analytics tools
-
Multi-speaker voice assistants
-
Speaker diarization models
Through data annotation outsourcing, companies can process large volumes of multi-speaker recordings efficiently while maintaining high annotation accuracy.
Language-Specific Transcription
Language-specific transcription involves transcribing speech in a particular language or dialect. This type of transcription may also account for regional accents, colloquial expressions, and cultural nuances.
Importance for Global AI Applications
As speech-enabled technologies expand globally, AI systems must understand multiple languages and dialects. High-quality language-specific datasets help ensure accurate speech recognition across diverse populations.
Examples include:
-
Multilingual voice assistants
-
Global customer service automation
-
Regional speech recognition models
Organizations frequently partner with an experienced data annotation company that has access to native-language annotators who understand linguistic variations.
The Importance of High-Quality Transcription for AI
The success of AI speech systems largely depends on the quality of the training data. Poor transcription can introduce errors that negatively affect model performance.
Key qualities of effective speech transcription datasets include:
Working with a specialized audio annotation company ensures that transcription projects are handled by trained professionals who follow standardized annotation processes.
Many organizations also adopt audio annotation outsourcing to accelerate dataset production while maintaining strict quality control standards.
Conclusion
Speech-enabled AI technologies continue to evolve, transforming the way humans interact with machines. Behind every accurate voice assistant, transcription service, or speech recognition system lies a carefully curated dataset built through precise speech transcription.
Different transcription types—such as verbatim, clean read, intelligent, phonetic, time-stamped, and speaker-labeled transcription—serve unique purposes in AI dataset creation. Each method contributes to improving the accuracy, adaptability, and linguistic understanding of AI models.
As demand for high-quality speech datasets grows, businesses increasingly rely on data annotation outsourcing and audio annotation outsourcing to scale their data preparation efforts. Partnering with an experienced data annotation company ensures that transcription datasets meet the accuracy and quality standards required for advanced AI development.
By choosing the right transcription approach and working with a trusted audio annotation company, organizations can build robust speech datasets that power the next generation of intelligent voice-driven technologies.



































 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0










