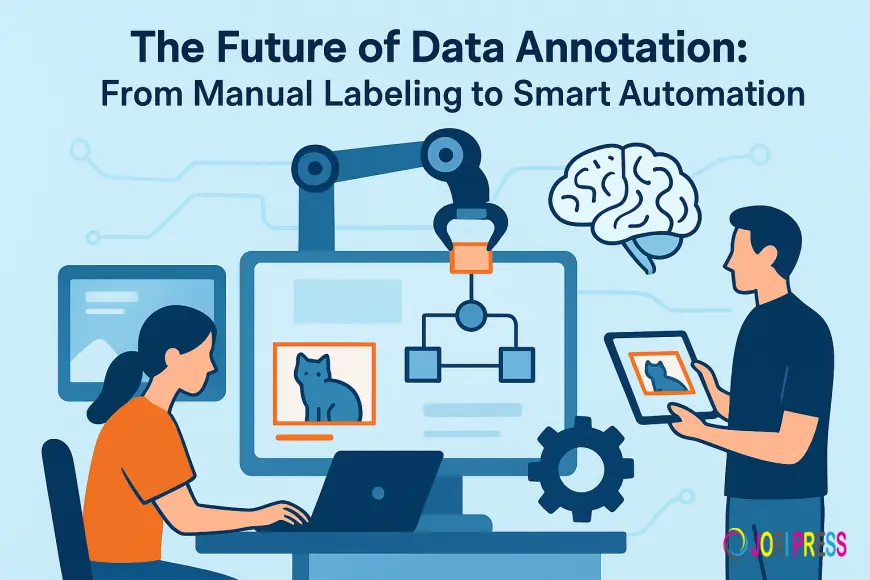
For years, armies of human annotators meticulously tagged images, transcribed speech, and classified text so models could learn. But as AI use-cases broaden and datasets explode in size and complexity, the old paradigm of purely manual labeling is reaching its limits. The future lies in hybrid approaches that blend human expertise with automation, intelligent tooling, and governance — unlocking scale without sacrificing quality.
Why manual annotation alone can’t scale
Manual labeling remains the gold standard for accuracy, especially in nuanced tasks (medical imaging, legal text, safety-critical sensor data). However, it has three fundamental constraints:
-
Cost and speed: High-quality human labeling is expensive and slow. Large-scale projects — think millions of frames for autonomous vehicles — become prohibitively expensive if fully manual.
-
Consistency: Different annotators interpret edge cases differently. Maintaining consistent labels across annotators and projects requires heavy QA and retraining.
-
Expertise bottlenecks: Some domains require specialized knowledge (radiology, geospatial analysis). Experts are scarce and costly; their time is best used for tasks that automation cannot handle.
These limitations are intensifying as models demand more diverse, multimodal, and continuously updated datasets.
Smart automation: what it means
Smart automation isn’t about replacing humans; it’s about elevating them. It includes a set of techniques and tools that automate repetitive, high-volume, or low-complexity parts of annotation workflows while keeping humans in the loop for validation, correction, and handling hard cases. Key elements include:
-
Pre-labeling with models: A pre-trained model generates initial labels which humans then verify and correct. This reduces human workload and accelerates throughput.
-
Active learning: The system selects the most informative or uncertain samples for human labeling, maximizing model improvement per label.
-
Weak supervision & programmatic labeling: Rules, heuristics, and noisy label sources are combined to produce large amounts of labeled data with less human effort, later refined by models and spot checks.
-
Semi-supervised and self-supervised learning: Models learn from unlabeled data directly, using a small seed of labeled examples to bootstrap performance.
-
Auto-segmentation and object tracking: For video or dense image tasks, algorithms propagate labels across frames or similar objects, dramatically cutting human time per frame.
-
Quality assurance automation: Automated consistency checks, label disagreement detection, and synthetic test cases identify problematic labels at scale.
Human + machine: the hybrid workflow
The most effective annotation pipelines are hybrid. Here’s a simplified lifecycle:
-
Data ingestion & normalization: Raw data is collected, deduplicated, and normalized.
-
Model-assisted pre-labeling: Existing models or heuristics provide initial annotations.
-
Active selection for human review: The system prioritizes uncertain, diverse, or safety-critical samples for expert annotators.
-
Human validation & correction: Annotators focus on high-value tasks — boundary cases, domain-specific nuance, and overall context.
-
Automated QA and feedback loop: Statistical QA and spot-checks identify errors; corrected labels are fed back to retrain the model.
-
Continuous monitoring: Model drift detection and periodic re-annotation ensure labels remain reliable as data distributions shift.
This loop minimizes expensive human time while maintaining high coverage and reliability.
Emerging technologies shaping annotation
Several advances are accelerating the transition to smart annotation:
-
Large foundation models: Pretrained multimodal models provide powerful starting points for pre-labeling across tasks (image, text, audio).
-
Edge and on-device annotation tools: Enabling annotation closer to data capture (e.g., in vehicles or medical instruments) reduces latency and privacy risk.
-
Explainability and uncertainty estimation: Models that can explain and quantify uncertainty help pick which labels need human attention.
-
Synthetic data and simulation: High-fidelity synthetic data supplements real data for rare events or privacy-sensitive domains.
-
Federated and privacy-preserving labeling: Collaboration without raw-data sharing protects privacy while expanding label pools.
-
Annotation orchestration platforms: Integrated platforms manage task routing, worker qualification, versioning, and audit trails.
Quality, governance, and ethics
Automation must not compromise trust. As annotation pipelines grow more automated, governance becomes critical:
-
Traceability: Every label should be traceable to its source (human, model, rule), with timestamps and versioning for audits.
-
Bias mitigation: Automated approaches can amplify biases in seed models or heuristics. Diverse training data, bias audits, and human oversight are essential.
-
Data privacy: Programmatic and federated approaches should obey privacy constraints; synthetic data can help where real data is sensitive.
-
Skillful human oversight: Annotators should be trained to catch model blind spots and to understand the broader context of tasks.
Investing in these governance practices protects downstream model integrity and reduces regulatory risk.
Business impact and ROI
Smart automation unlocks multiple business benefits:
-
Faster time-to-model: Automated pre-labeling and active learning shorten annotation cycles, accelerating experiments and deployments.
-
Lower marginal costs: As models improve, the human cost per label falls, enabling larger datasets within budget.
-
Higher model performance per dollar: Prioritizing high-value labels yields better performance improvements than brute-force labeling.
-
Better compliance posture: Traceability and governance reduce legal and reputational risks — increasingly important in regulated industries.
Organizations that invest in annotation automation can outpace competitors by iterating faster and deploying higher-quality models.
Looking ahead: human expertise reimagined
In the future, human annotators will shift from pure labelers to domain supervisors, data strategists, and curators. Their role will emphasize:
-
Designing label taxonomies and edge-case definitions.
-
Reviewing and resolving model uncertainties and adversarial cases.
-
Testing model behavior with curated scenarios.
-
Ensuring labels reflect social, cultural, and ethical considerations.
Annotation teams will become interdisciplinary, combining domain experts, data engineers, and ML practitioners working together in continuous feedback loops.
Conclusion
The trajectory from manual labeling to smart automation is not a simple replacement but a transformation of the annotation ecosystem. By combining human expertise with intelligent tooling, organizations can achieve the scale, speed, and quality modern AI demands — while maintaining accountability and reducing cost. The future of data annotation is hybrid, automated, and governed: a smarter pipeline that empowers humans to work on what truly matters while machines handle the repetitive heavy lifting. Partner with Annotera to harness the power of smart, scalable, and accurate data annotation.









































 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0








